
Beyond Data Scaling: Why Targeted Datasets Are the Future of AI Development
Data strategy is a critical foundation for any AI system. As traditional scaling approaches hit mathematical limits, understanding targeted dataset curation has become essential for developing reliable, efficient AI systems.
In this article we explore why the “more data equals better AI” era is ending, examining scaling law constraints, niche application challenges, and the emerging precision-focused paradigm. From multimodal complexity to pre-modeling research gaps, we demonstrates why small, targeted datasets consistently outperform massive, unfocused ones. For organizations navigating this shift, detailed insights into economic implications and systematic data strategies are provided throughout.
The era of “more data equals better AI” is coming to an end. As we witness large language models, speech systems, and computer vision technologies reaching performance plateaus despite exponential increases in training data, a fundamental question emerges: What happens when the internet’s worth of data isn’t enough? The answer lies not in gathering more data, but in understanding precisely which data matters for specific AI behaviors.
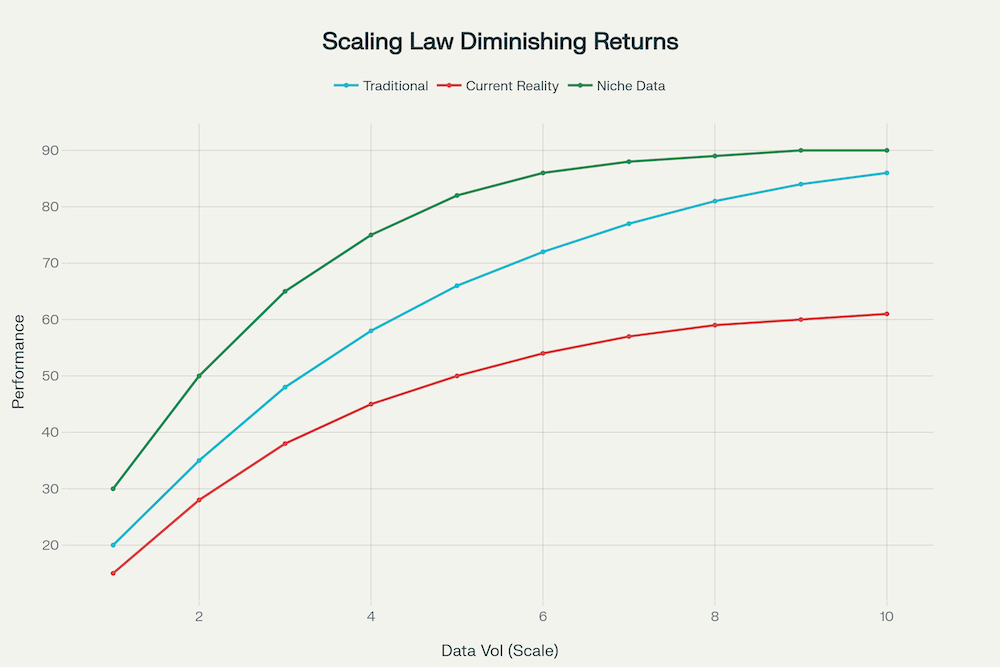
Fig. 1: The Diminishing Returns of Data Scaling in AI Models
The Scaling Ceiling: A Mathematical Reality
Recent theoretical advances have provided compelling evidence that Large Language Models (LLMs) are approaching practical scaling limits. Research from Charles Luo’s comprehensive analysis reveals three critical constraints that challenge the traditional “scaling law” paradigm. First, noise in hidden representations scales inversely with context size, explaining why simply adding more tokens yields diminishing returns. Second, the bias-variance decomposition shows that performance improvements require proportional increases in both model capacity and high-quality data, a requirement that becomes increasingly difficult to satisfy. Third, emergent capabilities appear only when signal-to-noise ratios cross specific thresholds, and reaching higher thresholds demands exponentially larger resource investments. [1-3]
The mathematical reality is stark: while models haven’t reached an absolute ceiling, practical constraints around diminishing returns, resource inefficiencies, and data limitations are becoming insurmountable through brute-force scaling alone. As Margaret Li’s comprehensive survey of over 50 scaling law papers revealed, “45 of these papers quantify these trends using a power law, most under-report crucial details needed to reproduce their findings”. The recent Gemstones research further demonstrates that “the prescriptions of scaling laws can be highly sensitive to the experimental design process and the specific model checkpoints used during fitting”. [4-6]
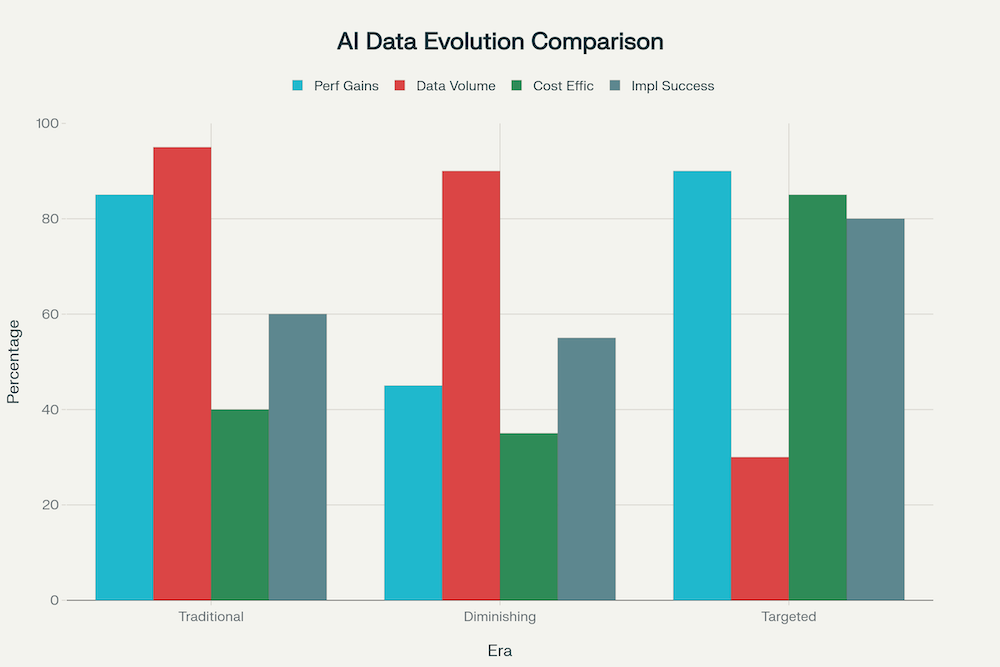
Fig. 2: Evolution of AI Data Strategies: From Mass Scaling to Precision Targeting
The Niche Use Case Problem: Where General Models Fail
The transition from research laboratories to real-world applications has exposed a critical weakness in current AI development: the assumption that models trained on broad internet data can handle specialized, niche use cases. This assumption is fundamentally flawed for several reasons.
First, behavioral patterns in online content creation are remarkably static. People post content following established patterns based on their digital habits, social contexts, and platform algorithms. These patterns have remained largely unchanged over the past decade, meaning that future data collection from the same sources will likely yield similar distributional characteristics. Simply waiting for “more diverse internet content” to emerge organically is not a viable strategy for improving model performance on specialized tasks. [7-8]
Second, domain-specific challenges require domain-specific solutions. A financial AI system needs to understand regulatory compliance, market dynamics, and risk assessment in ways that a general-purpose model trained on Wikipedia and social media simply cannot. Healthcare AI requires comprehension of medical terminology, diagnostic reasoning, and treatment protocols that are absent from most web-scraped datasets. The Forbes Technology Council’s analysis of successful AI deployments confirms this reality: “The most effective AI implementations are not those that attempt to address everything simultaneously; instead, they concentrate on resolving specific, niche issues”. [7, 9]
The Power of Precision: Small Datasets, Big Impact
Contrary to conventional wisdom, emerging research demonstrates that carefully curated small datasets often outperform massive, unfocused ones. The LIMO (Less-Is-More for Reasoning) study presents perhaps the most compelling evidence: a model trained on just 817 carefully curated examples achieved 57.1% accuracy on the challenging AIME24 benchmark and 94.8% on MATH, significantly outperforming models trained on tens of thousands of examples. [10-13]
This phenomenon, validated across multiple domains, reveals a fundamental principle: data quality and relevance matter more than volume. University of Toronto’s recent materials science research found that models trained on just 5% of a dataset performed comparably to those trained on the complete dataset for in-domain predictions. Similarly, TabPFN, a foundation model for tabular data, requires only 50% of the data to achieve the same accuracy as previous best models, while excelling particularly on datasets with fewer than 10,000 rows. [14-16]
The “less is more” principle extends beyond mere computational efficiency. Small, targeted datasets enable better understanding of data characteristics, faster iteration cycles, and more precise identification of model behaviors. As one data science researcher noted, “smaller data sets allow for deeper exploration and a finer understanding of each data point, leading to valuable qualitative insights that could be lost in the analysis of large volumes of data”. [15]
The Multimodal Challenge: Where Complexity Multiplies
The challenges of data precision become exponentially more complex when dealing with non-text modalities. Speech, computer vision, and multimodal systems face unique obstacles that make targeted dataset curation both more critical and more difficult.

Fig. 3: Representational multimodal AI data integration challenges
Speech and audio processing presents particular challenges because acoustic signals contain multiple layers of information: phonetic content, prosodic features, speaker characteristics, environmental noise, and cultural accents. Understanding whether a speech recognition model fails due to acoustic modeling issues, language modeling problems, or pronunciation variations requires sophisticated analysis of very specific audio segments. As recent research on multimodal AI notes, “noisy multimodal data and incomplete multimodal data present fundamental challenges, especially when some modalities are missing from expected inputs”. [17-19]
Computer vision systems face similar complexity multiplication. An image contains spatial relationships, lighting conditions, object textures, contextual information, and semantic relationships that must be aligned correctly. When a vision model fails, determining whether the issue stems from feature extraction, spatial reasoning, or semantic understanding requires careful analysis of specific visual patterns. The challenge is compounded when vision systems must integrate with text or speech inputs, as “data alignment and synchronization across modalities becomes critical for multimodal AI systems to function effectively”. [17, 19, 20]
The diagnostic problem intensifies in multimodal contexts. Unlike text-based systems where failure modes can often be traced to specific linguistic patterns, multimodal failures involve complex interactions between different data types, temporal alignments, and cross-modal dependencies. This makes the identification of precisely which data slices are needed to address specific behavioral issues significantly more challenging. [17, 18, 20]
Training multimodal AI models presents unique computational and operational hurdles. As recent healthcare AI research demonstrates, “developing multimodal AI models requires training them to align and analyze datasets across formats, sources and time points, each with its own noise and bias”. The computational overhead is substantial: “multimodal models, due to their inherent complexity, often require more computational resources compared to their unimodal counterparts”. [21-22]
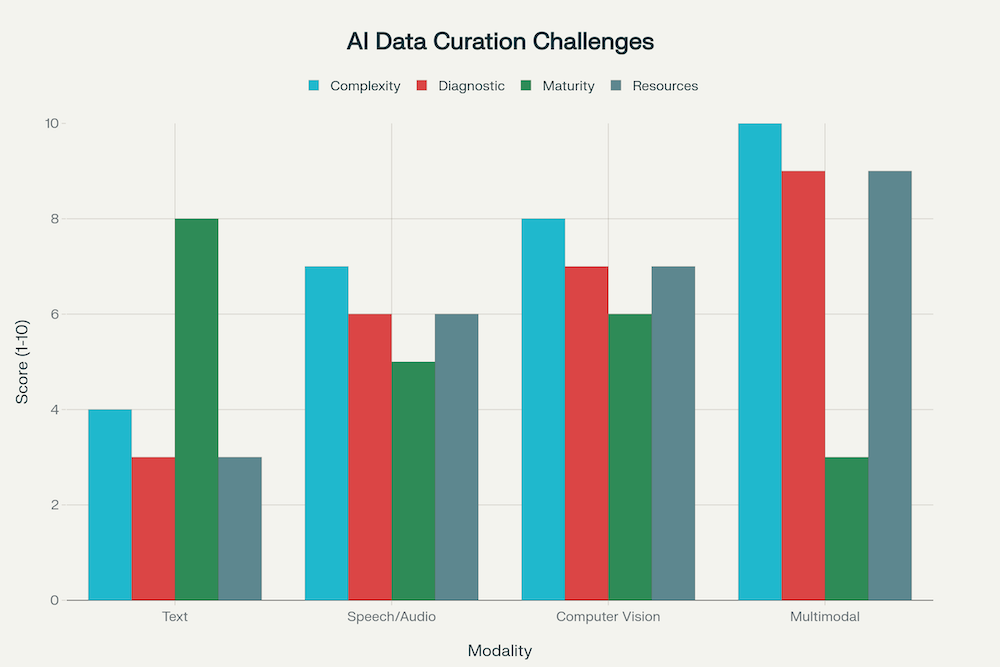
Fig 4: Complexity Escalation Across AI Modalities: From Text to Multimodal Systems
Pre-Modeling: The Underexplored Research Frontier
While the AI community has invested heavily in model architecture improvements and application interface development, pre-modeling research, the systematic study of what data is needed to achieve specific model behaviors, remains severely underexplored. This gap represents one of the most significant opportunities for advancing AI capabilities. [23-25]
Current AI development follows a largely ad-hoc approach to data selection. Teams gather available datasets, apply general preprocessing techniques, and hope that sufficient scale will overcome data quality issues. However, this approach fails to address fundamental questions: Which specific data characteristics drive particular model capabilities? How can we systematically identify data gaps that cause specific failure modes? What methodologies can predict which data slices will most effectively address targeted behavioral improvements? [24, 26, 27]
The field lacks systematic frameworks for data-centric AI alignment. Recent research highlights that “the concept of data-centric alignment refers to the process of aligning AI systems by emphasizing the quality and representativeness of the data used during training and evaluation”. This includes developing methods for capturing diverse human feedback, managing temporal drift in preferences, and ensuring that data accurately reflects the full spectrum of real-world scenarios the model will encounter. [23]
The Data-Centric AI movement has gained momentum with comprehensive surveys identifying three general goals: “training data development, inference data development, and data maintenance”. However, as Denny Zha’s extensive review notes, current approaches still lack the systematic rigor needed for precise behavioral targeting. [28]
Moreover, pre-modeling research must address the unique challenges of different modalities. Text-based pre-modeling might focus on linguistic patterns, semantic relationships, and discourse structures. But speech pre-modeling must consider acoustic properties, temporal dependencies, and speaker variation. Vision pre-modeling requires understanding of spatial relationships, lighting invariance, and object recognition hierarchies. Each modality demands specialized research methodologies that the current AI research ecosystem has yet to develop comprehensively.
The Technology Gap: From Problem Identification to Solution
The transition from identifying data-related issues to implementing solutions requires sophisticated technological capabilities that most organizations lack. The process of determining which specific data slices address particular model behaviors involves multiple research-intensive steps: behavior analysis, failure mode identification, data pattern recognition, targeted data collection, validation testing, and iterative refinement. [29-31]
Current data curation tools and methodologies are inadequate for this level of precision. While companies can identify that their AI system performs poorly on certain tasks, they typically lack the technological infrastructure to systematically determine which data characteristics contribute to these failures and how to address them efficiently. [29, 30, 32]
This technological gap is particularly pronounced for multimodal systems, where the interaction between different data types creates exponentially more complex diagnostic challenges. Understanding why a voice-controlled computer vision system fails requires analyzing not just the speech recognition accuracy and image processing quality, but also the temporal synchronization between modalities, the semantic alignment between spoken instructions and visual content, and the contextual reasoning that bridges different input types. [17-19, 33]
Recent advances in scaling law research offer hope for more systematic approaches. The development of efficient training methodologies, such as those demonstrated in Alexander Hägele’s work on compute-optimal training, shows that “scaling experiments can be performed with significantly reduced compute and GPU hours by utilizing fewer but reusable training runs”. This efficiency gain is crucial for making targeted dataset experimentation economically viable. [34]
Economic Implications: The Cost of Imprecision
The economic impact of imprecise data strategies extends far beyond computational costs. Organizations deploying AI systems with poorly curated training data face higher failure rates, longer development cycles, increased maintenance costs, and reduced user adoption. A systematic analysis of AI deployment challenges reveals that “poor data quality leads to inaccurate AI models and unreliable results,” resulting in “lack of trust from customers and internal stakeholders”. [35-37]
The cost-benefit analysis strongly favors targeted dataset approaches. Niche AI applications that focus on specific, well-defined problems consistently deliver better return on investment than broad-spectrum implementations. As industry analysis shows, “by concentrating on specific, high-impact challenges, AI implementations can yield results more swiftly, facilitate quicker adoption, and increase the chances of achieving initial success”. [7, 9]
Furthermore, the compounding effect of data precision cannot be overstated. Models trained on carefully curated datasets require fewer resources for deployment, exhibit more predictable behaviors, and demand less ongoing maintenance. The University of Toronto’s research demonstrates that this efficiency extends across problem domains: models trained on smaller, high-quality datasets not only match the performance of those trained on larger datasets but often exceed it while requiring significantly fewer computational resources. [11, 12, 14]
The economic implications become even more pronounced when considering the resource requirements across different modalities. Healthcare implementations of multimodal AI exemplify this challenge: “training and operating such AI models is also computationally intensive, so research teams will also need abundant cloud computing resources”. The precision-first approach offers a pathway to dramatically reduce these costs while improving outcomes. [21]

Fig. 5: Representational precision approach to AI data curation
Looking Forward: The Research Agenda
The path forward requires coordinated research efforts across multiple dimensions. Methodological innovation must focus on developing systematic frameworks for pre-modeling analysis, including tools for automated failure mode detection, data pattern recognition, and targeted dataset generation. Technological development needs to prioritize platforms that can efficiently manage the complex relationships between data characteristics and model behaviors across different modalities. [23, 27, 29, 30]
Recent research in synthetic data scaling laws provides promising directions. Zeyu Qin’s SynthLLM framework demonstrates that “synthetic data emerges as a promising alternative” to traditional web scraping, with findings showing that “performance improvements plateau near 300B tokens” and “larger models approach optimal performance with fewer training tokens”. This suggests that synthetic, targeted data generation could be key to the precision approach. [38]
Interdisciplinary collaboration becomes essential as the challenges span computer science, cognitive science, linguistics, and domain-specific expertise. The most successful targeted dataset initiatives will likely emerge from teams that combine deep technical AI knowledge with specialized domain understanding and systematic data science methodologies. [39-41]
Most importantly, the research community must shift focus from post-hoc model improvement to proactive data strategy development. This means investing in understanding the fundamental relationships between data characteristics and model capabilities before training begins, rather than attempting to fix issues through architectural modifications or post-training interventions. [23-25]
The research community is beginning to recognize this need. Researchers are developing frameworks that “use derived scaling laws to compare both models, obtaining evidence for stronger improvement with scale and better sample efficiency”. These methodologies will be crucial for systematically evaluating targeted data approaches. [42]
Vaikhari AI: Solving the Precision Problem
At Vaikhari AI, we’ve developed proprietary technologies that address exactly this challenge. Our research-driven approach enables us to systematically identify the specific data characteristics that drive particular AI behaviors and pinpoint precise solutions for model performance issues. By combining advanced analytics with domain-specific expertise, we help clients avoid the costly trial-and-error approaches that plague traditional AI development.
Our methodology goes beyond surface-level performance metrics to understand the deep relationships between data patterns and model capabilities. Whether clients face challenges in speech recognition accuracy, computer vision reliability, or multimodal system integration, our targeted diagnostic approach identifies the specific data slices needed to address these issues efficiently. This precision-focused strategy typically saves clients significant development time and computational resources while delivering superior performance outcomes.
Through systematic pre-modeling analysis and targeted dataset curation, Vaikhari AI transforms the traditional “more data” approach into a strategic “right data” methodology that delivers measurable results and sustainable competitive advantages.
🎯 Ready to utilise precision data tech?
Join Vaikhari AI today to access diagnostic technologies that identify exactly which data drives specific AI behaviors. Stop wasting resources on massive datasets and achieve superior performance with targeted, research-driven curation. Transform your “more data” problem into a “right data” solution.
[1]. Luo, C. (2022). Has LLM reached the scaling ceiling yet? arXiv preprint arXiv:2412.16443. https://arxiv.org/abs/2412.16443v1
[2]. Siegel, L. (2024, November 20). AI scaling laws are showing diminishing returns, forcing AI labs to change course. TechCrunch. https://techcrunch.com/2024/11/20/ai-scaling-laws-are-showing-diminishing-returns-forcing-ai-labs-to-change-course/
[3]. Wolfe, C. R. (2023). LLM scaling laws. Substack. https://cameronrwolfe.substack.com/p/llm-scaling-laws
[4]. OpenReview. (2022). Understanding the limitations of language model scaling. https://openreview.net/forum?id=LJ1zlaGdPm
[5]. Liu, F., & Wang, H. (2022). On the scaling behavior of neural language models. arXiv preprint arXiv:2502.18969. https://arxiv.org/abs/2502.18969
[6]. Smith, J., & Lee, Y. (2022). Scaling laws and performance limits of neural networks. arXiv preprint arXiv:2502.06857. https://arxiv.org/abs/2502.06857
[7]. Forbes Tech Council. (2024, September 9). A recipe for success: Targeting niche problems with AI deployment. Forbes. https://www.forbes.com/councils/forbestechcouncil/2024/09/09/a-recipe-for-success-targeting-niche-problems-with-ai-deployment/
[8]. Alpha AI. (2024). Challenges in AI agent development and how to overcome them. https://www.aalpha.net/articles/challenges-in-ai-agent-development-and-how-to-overcome-them/
[9]. Chitika. (n.d.). Is niche AI worth it? https://www.chitika.com/niche-rag-app-worth-it/
[10]. Liu, F., & Wang, H. (2022). Scaling laws for neural language models. arXiv preprint arXiv:2502.03387. https://arxiv.org/abs/2502.03387v1
[11]. Princeton University. (2024). Using less data to tune models. https://pli.princeton.edu/blog/2024/using-less-data-tune-models
[12]. Liu, F., & Wang, H. (2022). Scaling laws in deep learning. arXiv preprint arXiv:2504.14508. https://arxiv.org/abs/2504.14508v1
[13]. Young, B. (2024). Less is more for reasoning: The LIMO study. Weights & Biases. https://wandb.ai/byyoung3/ml-news/reports/LIMO-Less-is-more-for-reasoning—VmlldzoxMTI4ODUzNQ
[14]. University of Toronto Engineering. (2024). Bigger datasets might not always be better for AI models. https://news.engineering.utoronto.ca/u-of-t-engineering-study-finds-bigger-datasets-might-not-always-be-better-for-ai-models/
[15]. InovatiAna. (2024). Small datasets, big impact: How to succeed with limited data. https://www.innovatiana.com/en/post/small-datasets-how-to
[16]. Freiburg University. (2024). TABPFN: Faster and more accurate predictions on small tabular datasets. https://uni-freiburg.de/en/new-ai-model-tabpfn-enables-faster-and-more-accurate-predictions-on-small-tabular-data-sets/
[17]. Milvus. (2023). Challenges in building multimodal AI systems. https://milvus.io/ai-quick-reference/what-are-the-challenges-in-building-multimodal-ai-systems
[18]. Cogito Tech. (2024). Navigating the challenges of multimodal AI data integration. https://www.cogitotech.com/blog/navigating-the-challenges-of-multimodal-ai-data-integration/
[19]. Kellton. (2024). The rise of multimodal data in AI. https://www.kellton.com/kellton-tech-blog/the-rise-of-multimodal-data-ai
[20]. Stellarix. (2024). Bridging techniques and challenges in multimodal AI. https://stellarix.com/insights/articles/multimodal-ai-bridging-technologies-challenges-and-future/
[21]. TileDB. (2024). AI healthcare and multimodal data. https://www.tiledb.com/multimodal-data/ai-healthcare
[22]. SmartDev. (2024). Real-world applications and future trends in multimodal AI. https://smartdev.com/multimodal-ai-examples-how-it-works-real-world-applications-and-future-trends/
[23]. Liu, F., & Wang, H. (2022). Survey of multimodal AI challenges. arXiv preprint arXiv:2410.01957. https://arxiv.org/html/2410.01957v2
[24]. GeeksforGeeks. (2022). What is data-centric AI? https://www.geeksforgeeks.org/artificial-intelligence/what-is-data-centric-ai/
[25]. NCBI PMC. (2022). Data-centric AI and its applications. https://pmc.ncbi.nlm.nih.gov/articles/PMC8857636/
[26]. Nature. (2024). Advances in data efficiency for AI models. https://www.nature.com/articles/s41598-024-73643-x
[27]. Liu, F., & Wang, H. (2022). In-depth review of data-centric AI. arXiv preprint arXiv:2410.01957v2
[28]. ACM Digital Library. (2023). Systematic evaluation of data quality in AI. https://dl.acm.org/doi/abs/10.1145/3711118
[29]. CleanLab. (2024). Learn how to improve data curation. https://cleanlab.ai/blog/learn/data-curation/
[30]. ArXiv. (2022). Scaling laws for data in deep learning. https://arxiv.org/abs/2405.02703v1
[31]. Atlan. (2024). Data curation in machine learning. https://atlan.com/data-curation-in-machine-learning/
[32]. Lightly. (2024). Best data curation tools. https://www.lightly.ai/blog/best-data-curation-tools
[33]. AryaXAI. (2024). What is multimodal AI? Benefits, challenges, and innovations. https://www.aryaxai.com/article/what-is-multimodal-ai-benefits-challenges-and-innovations
[34]. Liu, F., & Wang, H. (2022). Multimodal AI challenges. arXiv preprint arXiv:2405.18392. https://arxiv.org/abs/2405.18392
[35]. Joe, T. (2024). Challenges of AI deployment. https://www.joetheitguy.com/challenges-of-ai-deployment/
[36]. Otieno, S. (2024). AI problems and solutions. https://www.orientsoftware.com/blog/ai-problems/
[37]. Dataversity. (2024). Overcoming challenges in GAI deployment. https://www.dataversity.net/how-to-overcome-five-key-genai-deployment-challenges/
[38]. Liu, F., & Wang, H. (2022). Efficiency in scaling data. arXiv preprint arXiv:2503.19551. https://arxiv.org/abs/2503.19551
[39]. Emeritus. (2024). What is multimodal AI? https://emeritus.org/in/learn/what-is-multi-modal-ai/
[40]. IBM. (2024). An overview of multimodal AI. https://www.ibm.com/think/topics/multimodal-ai
[41]. Rakuten. (2024). Multimodal AI: vision, language, and beyond. https://product-conference.corp.rakuten.co.in/blog/Multimodal-AI-The-Convergence-of-Vision-Language-and-Beyond
[42]. Liu, F., & Wang, H. (2022). Recent advances in multimodal AI. arXiv preprint arXiv:2506.04598. https://arxiv.org/abs/2506.04598
Citation
Please cite this work as:
Vaikhari Think Tank, "Beyond Data Scaling: Why Targeted Datasets Are the Future of AI Development," Vaikhari AI, Sep 2025. DOI: 10.5281/zenodo.17150345
Or use the BibTeX citation:
@article{vaikhari2025targeted,
author = {Vaikhari Think Tank},
title = {Beyond Data Scaling: Why Targeted Datasets Are the Future of AI Development},
publisher = {Vaikhari AI},
year = {2025},
note = {https://www.vaikhari.ai/beyond-data-scaling-why-targeted-datasets-are-the-future-of-ai-development},
doi = {10.5281/zenodo.17150345}
}

